Zusammenfassung
Im ersten Teil prüfen wir gängige Thesen zur KI in der Softwareentwicklung: Kann jetzt jede:r entwickeln? Wird Problemlösen überflüssig? Und führt KI automatisch zu mehr Effizienz? Unsere Auswertungen zeigen ein differenzierteres Bild: Nicht blinder Einsatz, sondern unterschiedliche Nutzungsweisen. Entscheidend ist dabei die KI-Kompetenz: Wer Architektur und Softwareverständnis mitbringt, nutzt KI gezielter und erzeugt nachweislich besseren Code.
Im zweiten Teil betrachten wir vier zentrale Verschiebungen: begrenztes Vertrauen in KI-Ergebnisse, mehr Output ohne automatisch bessere Qualität, die wachsende Bedeutung von Review und die Lücke zwischen schnellen Prototypen und produktionsreifer Software
Von Vorurteil und Paradox zum Narrativ
Wir haben einige der vielen Aussagen rund um KI in der Softwareentwicklung für uns eingeordnet:
Kann jetzt jede:r entwickeln?
Wird Programmieren überflüssig?
Und führt KI automatisch zu mehr Effizienz?
Besonders relevant für uns, da sich nicht nur unsere Arbeitsweise, sondern auch unser Geschäftsmodell verändert.
Disclaimer: Als Softwareentwicklungs-Unternehmen sind wir bei diesem Thema nicht vollständig neutral. Um die Diskussion möglichst sachlich zu führen, orientieren wir uns eng an unserer tatsächlichen Nutzung, eigenen aggregierten Auswertungen und der aktuellen Studienlage. Die Auswertung von Daten und die Veröffentlichung aggregierter Ergebnisse wurden vorab transparent mit dem Team abgestimmt.
Die wichtigsten Ergebnisse vorab:
| Ergebnis | Einordnung | Verweis im Text |
|---|---|---|
| Entwickler:innen werden 10-20% produktiver | Feldstudien zeigen messbare Produktivitätszuwächse, aber nicht automatisch bessere Qualität oder Stabilität. | „Vom Implementieren zum Orchestrieren“ |
| Ca. 30% der KI-Vorschläge werden übernommen | Ein großer Teil der KI-Vorschläge wird verworfen oder angepasst. | „Führt KI automatisch zu mehr Effizienz?“ |
| 3 Iterationen/Prompts bis KI Code angenommen wird | Vorschläge werden iteriert, verworfen und angepasst statt direkt übernommen. | „Wird Programmieren überflüssig?“ |
| Zweifeln an KI-Genauigkeit | Trust Gap: KI ist im Alltag angekommen, bleibt aber prüfpflichtig. | „Vom Implementieren zum Orchestrieren“ |
| KI-Code produziert ca. 1,7x mehr Fehler | Mehr Output heißt nicht automatisch bessere Qualität. Review wird zentral. | „Review wird wichtiger als Writing“ |
| KI beschleunigt Prototyping | Erste Versionen entstehen schneller, Produktreife bleibt aufwendig. | „Rapid Prototyping wird Standard“ |
| Shift Left | Qualität verschiebt sich nach vorne: Testfälle oder Spezifikationen unterstützen bei KI-Code | "Shift Left: Qualität verschiebt sich nach vorne" |
Ein Teil unseres Teams nutzt GitHub Copilot, einen KI-Agenten, der bei der Softwareentwicklung unterstützt, bereits aktiv und sammelt erste Erfahrungen im Alltag. Mitte April haben wir den Einsatz auf alle Entwickler:innen ausgeweitet und begleiten diesen Schritt:
Wir wollen verstehen, was sich tatsächlich verändert und was nur als Narrativ im Raum steht, denn zwischen Hype, Skepsis und widersprüchlichen Erfahrungen entstehen oft (Vor-)Urteile, die sich festsetzen und Orientierung suggerieren. Aber was davon trifft zu?
Wir sind ein kleines Team von rund 20 Entwickler:innen und haben die gängigsten Thesen bewusst auf unsere eigene Arbeitsweise übertragen und auf die Probe gestellt, um daraus ein eigenes Bild abzuleiten. Nicht als allgemeingültige Wahrheit, sondern als Arbeitsgrundlage für uns. Unser Ziel ist es, ein für uns konsistentes Narrativ zu entwickeln, das uns hilft, bessere Entscheidungen im Umgang mit KI zu treffen insbesondere mit Blick auf den breiteren Rollout im Team.
Viele der folgenden Thesen werden bekannt vorkommen. Sie prägen aktuell die Diskussion und wirken oft intuitiv richtig. Genau deshalb lohnt es sich, genauer hinzuschauen. Auch wenn sich nicht alles aus unserer kleinen Nutzergruppe heraus generalisieren lässt, lohnt sich der Blick und Übertrag für alle Organisationen.
Zur Methodik
Über die GitHub Copilot Usage Schnittstelle lassen sich Telemetrie-Daten zur tatsächlichen Nutzung von Copilot als KI-Agent in der Softwareentwicklung gewinnen. Dazu gehören unter anderem Interaktionen, genutzte Features, zeitliche Nutzungsmuster sowie Kontextinformationen auf Nutzerebene.
Auf dieser Grundlage haben wir eigene, vereinfachte Kennzahlen abgeleitet, die uns helfen, Nutzung und Verhalten im Kontext der folgenden Thesen besser einzuordnen. Wichtig ist dabei: Diese Metriken messen nicht direkt Qualität, Kompetenz oder Vertrauen, sondern dienen als Proxy für beobachtbares Verhalten und Adoption.
Dafür haben wir unsere Entwickler:innen den Rollen Junior bis Senior zugeordnet und vergleichen die Thesen im Folgenden auf diesem Aggregationslevel.
Thesen auf der Probe
Wir haben drei der aktuell häufig zitierten Aussagen zu KI in der Softwareentwicklung genauer untersucht. Viele dieser Aussagen drehen sich um die zentrale Frage, ob KI die Softwareentwicklung so grundlegend verändert, dass klassische Rollen an Bedeutung verlieren. Die zunehmende „Demokratisierung“ in der Programmierung durch natürliche Sprache legt genau das nahe:
Die Software-Entwicklung wird zugänglicher, schneller und weniger abhängig von tiefem technischem Wissen.
Um das besser zu verstehen, haben wir unsere eigenen Nutzungsdaten und Erfahrungen den gängigen Thesen gegenübergestellt. Für jede These stellen wir eine eigene Auswertung vor. Zunächst betrachten wir die Auswertungen einzeln, ordnen sie dann aber auch gemeinschaftlich ein, da sich die Ergebnisse teilweise gegenseitig stützen.
“Entwickler:innen verlassen sich blind auf KI. Oder: Kann jetzt jede:r entwickeln?”
Zur Überprüfung der These haben wir ausgewertet, wie unsere Entwickler:innen KI-generierten Code in der täglichen Arbeit übernehmen. In der Auswertung haben wir die Anzahl der generierten Codezeilen (Lines of Code, LOC) über den Zeitverlauf betrachtet. Dabei unterscheiden wir zwei zentrale Metriken.
Effective LOC: das Verhältnis von erzeugten Codezeilen pro Generierung, also beispielsweise pro Prompt
Total LOC: die Gesamtanzahl der erzeugten Codezeilen
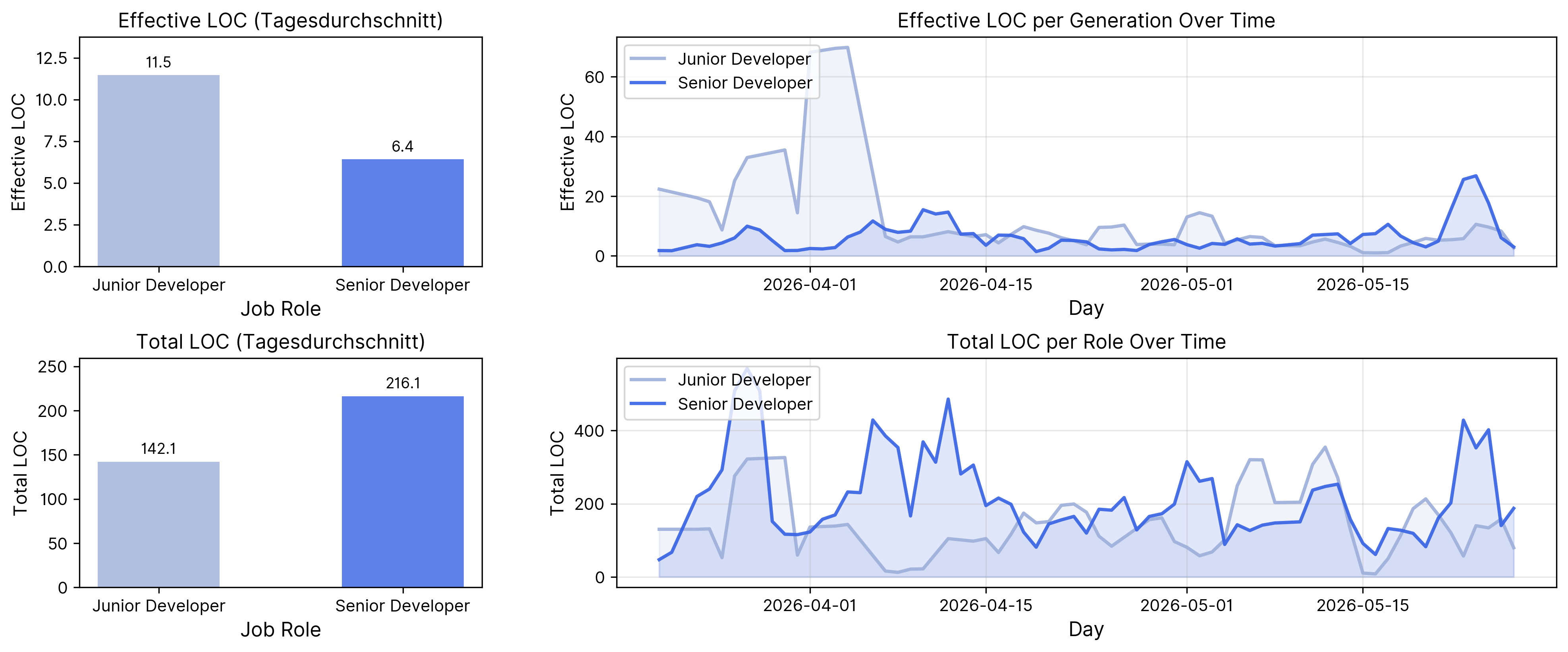
Die Auswertung zeigt, dass Senior-Entwickler:innen im Tagesdurchschnitt deutlich mehr Code über KI-Agenten erzeugen als Junior-Entwickler:innen (382 vs. 199 LOC). Gleichzeitig liegen Juniors bei den Effective LOCs über den Seniors: Pro Generierung entstehen also im Schnitt größere Codeblöcke.
Das deutet auf unterschiedliche Arbeitsweisen hin:
Senior-Entwickler:innen arbeiten kleinteiliger und iterativer: Sie erzeugen insgesamt mehr Code, verteilen diesen aber auf mehr, kleinere Generierungen.
Junior-Entwickler:innen hingegen erzeugen pro Prompt größere Einheiten. Das kann darauf hindeuten, dass sie versuchen, mehr Aufgaben in einer einzelnen Generierung zu bündeln.
Je nach Kompetenz und Erfahrung werden KI-Agenten in der Softwareentwicklung unterschiedlich und unterschiedlich effizient genutzt. Der Vergleich zwischen Junior- und Senior-Entwickler:innen zeigt, dass Erfahrung einen Einfluss darauf haben kann, wie gezielt KI eingesetzt wird. Auch wenn Programmierung durch KI für eine breitere Masse zugänglicher wird, bedeutet das nicht, dass alle Nutzer:innen die Ergebnisse gleichermaßen einordnen, bewerten und verantworten können. Gerade bei Personen ohne Entwicklungshintergrund dürfte sich daher noch einmal ein anderes Nutzungsmuster zeigen als bei Junior-Entwickler:innen. Offen bleibt, ob die unterschiedliche Verwendung auch einen Einfluss auf die Ergebnisse hat?
“KI macht Softwareentwicklung einfacher. Oder: Führt KI automatisch zu mehr Effizienz?”
Softwareentwicklung ist über die letzten Jahrzehnte kontinuierlich zugänglicher geworden, nun insbesondere durch KI-Agenten. Programmiersprachen sind allerdings auch in der Vergangenheit bereits immer zugänglicher geworden. So haben sich Sprachen von systemnahen, komplexen Sprachen hin zu höher abstrahierten, leichter zugänglichen Konzepten entwickelt. Mit der Nutzung natürlicher Sprache durch KI-Modelle wird diese Entwicklung aber nochmal verstärkt.
Um diese These besser einzuordnen, betrachten wir in dieser Auswertung den Umfang des generierten Codes, der in unsere Projekte einfließt. Dafür nutzen wir die folgende Metrik:
Suggestion-Acceptance Rate: der Anteil von durch KI vorgeschlagenem Code (LOC), der am Ende tatsächlich übernommen und in die Codebasis integriert wird
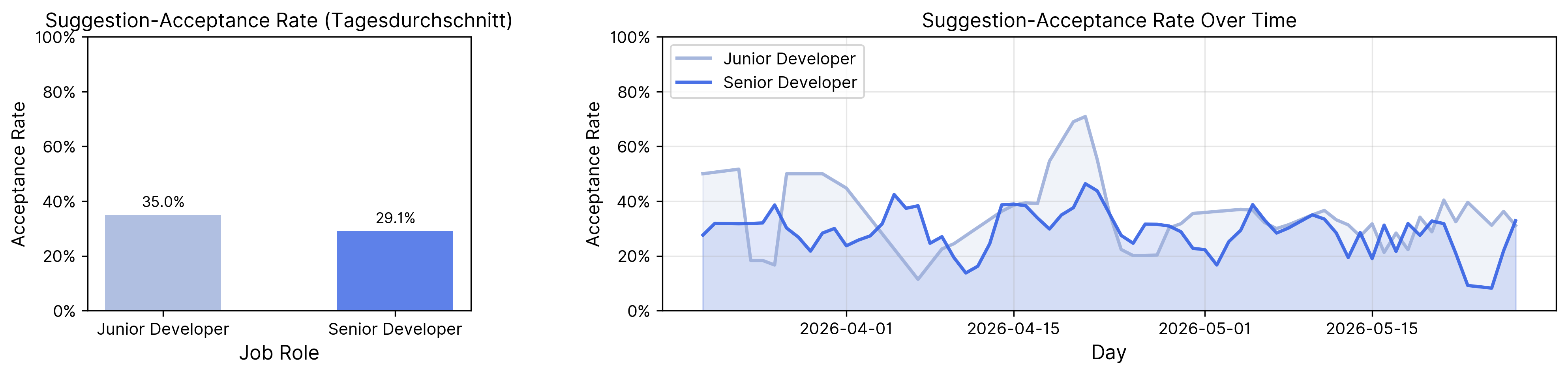
Die Auswertung zeigt, dass Junior-Entwickler:innen mit 35,0 % einen höheren Anteil der generierten Vorschläge übernehmen als Senior-Entwickler:innen mit 29,1 %. Über den Nutzungszeitraum lässt sich allerdings erkennen, dass mit zunehmender Nutzung und Erfahrung sich die Akzeptanzraten annähern.
Das deutet darauf hin, dass sich die Bewertung von KI-Vorschlägen je nach Erfahrung unterscheidet. Senior-Entwickler:innen scheinen selektiver zu entscheiden, welche Vorschläge sie übernehmen und welche nicht. Wären die Vorschläge durchgängig passend, korrekt und kontextgerecht, wäre zu erwarten, dass auch erfahrene Entwickler:innen einen höheren Anteil übernehmen.
KI öffnet den Zugang zur Softwareentwicklung, aber die Qualität des Einsatzes bleibt von Erfahrung abhängig. Die vergleichsweise niedrigen Annahmequoten von generiertem Code zeigen, dass selbst erfahrene Entwickler:innen einen großen Teil der Vorschläge bewusst verwerfen oder anpassen, weil sie nicht den Anforderungen an Qualität, Architektur oder Wartbarkeit entsprechen. Unter der Annahme, dass Menschen effiziente Wege nutzen, wenn sie zuverlässig funktionieren, spricht das gegen die These, dass KI automatisch zu mehr Effizienz führt. Auch wenn heute mehr Menschen Code erzeugen können, heißt das nicht automatisch, dass dieser Code für produktive Systeme geeignet ist. Der Mehrwert liegt daher oft eher in frühen, prototypischen Phasen und entsteht dann wenn Vorschläge sauber weiterentwickelt werden.
“KI wird zum Ersatz für eigenes Problemlösen. Oder: Wird Programmieren überflüssig?”
Der klassische Lern- und Problemlösungszyklus in der Softwareentwicklung basiert auf Iteration: Code schreiben, Fehler machen, Ursachen verstehen, neue Ideen entwickeln und bessere Lösungen ableiten. Dieser Feedback-Loop kann sich verkürzen, wenn KI Vorschläge liefert, die direkt übernommen werden, ohne dass sich Entwickler:innen tiefer mit dem eigentlichen Problem auseinandersetzen.
Das lässt sich auch positiv interpretieren: Wenn KI mehr Umsetzung übernimmt, werden bestimmte Entwicklungsaufgaben auch für Menschen ohne klassischen Softwareentwicklungs-Hintergrund zugänglicher. Die zentrale Frage bleibt aber, ob KI damit wirklich Problemlösung ersetzt oder nur verschiebt, wo sie stattfindet. Denn KI generiert Vorschläge auf Basis gelernter Muster und nicht aus einem eigenen Verständnis von Systemkontext. Ob das bereits als echte Intelligenz gilt, gehört eher in die AGI-Debatte. AGI steht für „Artificial General Intelligence“, also eine KI, die Aufgaben ähnlich flexibel und eigenständig lösen könnte wie ein Mensch.
Um diese These besser einzuordnen, betrachten wir Nutzungsmuster, die Breite der Einbettung in den Entwicklungsalltag und die Anzahl der Iterationen bis zur Annahme einer vorgeschlagenen Lösung. Sie dienen uns als Indikator dafür, ob KI eher als direkter Lösungsgeber oder als Unterstützung im Problemlösungsprozess eingesetzt wird.
Für die Analyse betrachten wir zwei zentrale Metriken:
Workflow Embeddedness: Wie breit ist KI im Entwicklungsalltag einer Rolle verankert? Dafür betrachten wir nicht nur, ob Copilot genutzt wird, sondern wie viele Entwickler:innen einer Rolle regelmäßig aktiv sind, in wie vielen Wochen Nutzung stattfindet und wie breit sich die Nutzung über Features und Sprachkontexte verteilt. Der Workflow-Embeddedness-Score setzt sich aus Weekly Presence (10 %), User Spread (35 %), Feature Breadth (30 %) und Language Breadth (25 %) zusammen und gewichtet damit vor allem, wie breit Copilot über Personen, Features und Sprachkontexte hinweg im Arbeitsalltag verankert ist.
Adoption Quadrant: Der Quadrant verdichtet diese Einbettung auf zwei Dimensionen. User Spread zeigt, wie groß der Anteil aktiver Entwickler:innen innerhalb einer Rolle ist. Context Breadth zeigt, wie breit Copilot über Features und Sprachgruppen hinweg eingesetzt wird. Dadurch wird sichtbar, ob Nutzung nur punktuell stattfindet oder tatsächlich breiter im Workflow angekommen ist.
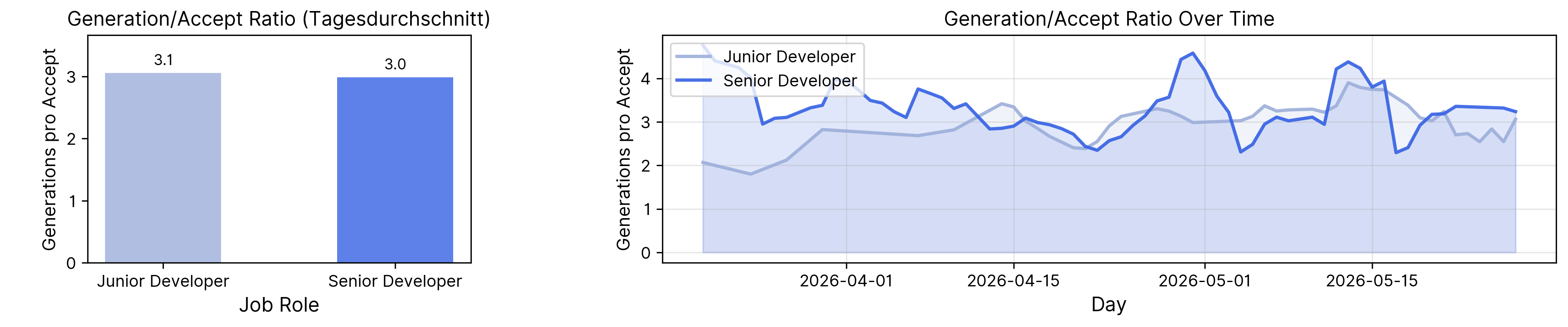
Generation/Accept Ratio: Wie viele angestoßene Generierungen beziehungsweise Prompts nötig sind, bis daraus Codevorschläge angenommen werden.
Die Werte betrachten wir sowohl über den Zeitverlauf als auch als durchschnittliche Tageswerte.
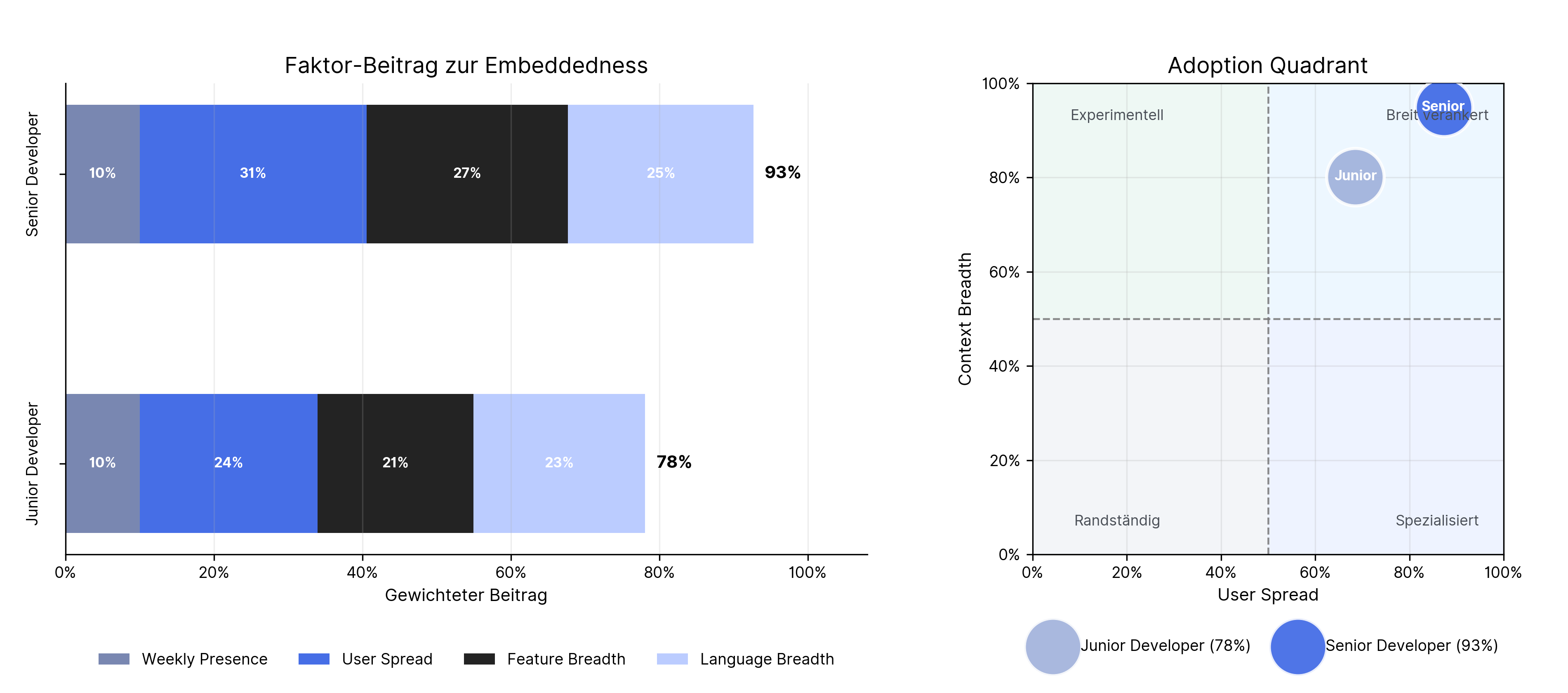
Die Auswertung zeigt, dass KI nicht nur vereinzelt genutzt wird, sondern in beiden Rollen sichtbar im Entwicklungsalltag angekommen ist. Gleichzeitig unterscheidet sich die Breite der Einbettung.
Senior-Entwickler:innen weisen eine höhere Workflow Embeddedness auf, weil bei ihnen sowohl der Anteil aktiver Nutzer:innen als auch die Breite der Nutzungskontexte stärker ausgeprägt ist. Der Faktor-Beitrag zur Embeddedness macht sichtbar, woher diese Unterschiede kommen. Der Score setzt sich aus Weekly Presence, User Spread, Feature Breadth und Language Breadth zusammen. Damit misst er nicht einfach nur Häufigkeit, sondern ob KI über mehrere Wochen hinweg, durch mehrere Personen und in unterschiedlichen Arbeitskontexten genutzt wird.
Der Adoption Quadrant ergänzt diese Sicht. Er zeigt, ob Copilot nur von wenigen Personen oder in engen Kontexten genutzt wird, oder ob die Nutzung breit über Rolle und Aufgabenbereiche verankert ist. Besonders relevant ist dabei die Kombination aus User Spread und Context Breadth: Eine hohe Position im Quadranten spricht dafür, dass KI nicht nur ausprobiert wird, sondern stärker Teil des regulären Entwicklungsworkflows geworden ist.
Damit sprechen die Daten eher für eine breite, aber weiterhin rollenabhängige Einbettung von KI in den Entwicklungsworkflow. KI wird nicht einfach dauerhaft anstelle eigener Arbeit genutzt, sondern unterschiedlich stark in bestehende Arbeitsweisen integriert. Besonders bei Seniors wirkt Copilot stärker wie ein reguläres Werkzeug im Workflow, während die Nutzung bei Juniors weniger breit verteilt ist.
In Ergänzung dazu zeigt die Generation/Accept Ratio, wie viele Generierungen im Schnitt notwendig sind, bis ein Vorschlag angenommen wird. Ein Wert von 3 bedeutet also: Im Durchschnitt werden drei Vorschläge erzeugt, bevor einer übernommen wird. Das ist ein Hinweis darauf, inwieweit KI-Ergebnisse direkt verwendet werden können oder ob ein Auswahl-, Bewertungs- und Verbesserungsprozess notwendig ist.
Junior- und Senior-Entwickler:innen haben ein fast gleiches Verhältnis mit einem Wert von rund 3. Der oft vermutete Unterschied, dass Junior-Entwickler:innen Vorschläge schneller übernehmen und Senior-Entwickler:innen deutlich kritischer iterieren, lässt sich anhand dieser Metrik nicht bestätigen. Beide Gruppen durchlaufen einen ähnlichen Iterationsprozess, bevor Code verwendet werden kann.
Der Unterschied liegt daher weniger darin, ob KI-Vorschläge geprüft und verworfen werden, sondern eher darin, wie breit und selbstverständlich dieser Prozess in den Workflow eingebettet ist. Senior-Entwickler:innen scheinen KI nicht einfach nur häufiger zu nutzen, sondern stärker über verschiedene Kontexte hinweg einzusetzen. In Verbindung mit den vorherigen Auswertungen, etwa zu Effective Lines of Code, deutet das darauf hin, dass Erfahrung weiterhin eine wichtige Rolle spielt.
KI ersetzt eigenes Problemlösen nicht. Sie unterstützt dabei, Varianten zu erzeugen, aber Entwickler:innen müssen weiterhin Ziele formulieren, Vorschläge bewerten und entscheiden, was übernommen wird. Programmieren wird dadurch nicht überflüssig, sondern verlagert sich stärker auf Steuerung, Review und Kontextverständnis. Unsere Auswertungen zeigen: Erfahrung bleibt relevant, weil sie beeinflusst, wie gut KI-Ergebnisse eingeordnet und in belastbare Software überführt werden.
Shift Left, Shift Up: Wie sich die Arbeit als Entwickler:in verändert
In den vorigen Abschnitten haben wir häufig zitierte Thesen diskutiert. Nun treten wir einen Schritt zurück und schauen auf Veränderungen im Alltag der Softwareentwicklung. KI wird breit genutzt, ihre Ergebnisse müssen jedoch weiterhin geprüft werden. Es zeigen sich vier zentrale Verschiebungen, die die Entwicklungsarbeit verändern:
Vom Implementieren zum Orchestrieren
Die aktuelle Forschung bestätigt, dass sich die Rolle von Softwareentwickler:innen vom manuellen Implementieren hin zum Orchestrieren von KI-Agenten verschiebt ¹ ². Anstatt Code zu schreiben, steuern Entwickler:innen heute Ziele, Spezifikationen und Workflows für KI-Agenten und prüfen deren Ergebnisse. Dieses neue Paradigma erfordert andere Fähigkeiten. Insbesondere die präzise Formulierung von Anforderungen und Prompts gewinnen an Bedeutung ¹. Entwickler:innen verwenden mehr Zeit auf Planung und Review (z.B. „Problem Framing“ und Spezifikationssicherheit) und weniger auf das reine Schreiben/Programmieren ¹ ². Für die Entwickler:innen-Rollen bedeutet dies iterativere und parallelere Abläufe zu steuern. Mehrere KI-gestützte Ansätze werden gleichzeitig generiert und später konsolidiert.
Empirische Umfragen bestätigen jedoch, dass das Vertrauen in KI-Ausgaben begrenzt ist. So geben nur etwa 43 % der Befragten an, der Genauigkeit von KI-Ergebnissen zu vertrauen. Besonders bei komplexeren Aufgaben wird diese Einschätzung zurückhaltender³. Andere Studien zeigen, dass 96 % der Entwickler:innen nicht vollständig davon überzeugt sind, dass KI-generierter Code funktional korrekt ist⁶. Verallgemeinert lässt sich daraus ableiten, dass weiterhin basierend auf praktischen Erfahrungen mit fehlerhaften und unvollständigen Ergebnissen, Misstrauen besteht. Risiken bestehen insbesondere in erhöhter Komplexität und Koordinationsaufwand beim Einsatz mehrerer Agenten (es gibt keinen spezifischen Peer-Review-Fund) sowie in fehlerhaften oder unsicheren Vorschlägen. Ungeachtet der Automatisierung bleibt die letztliche Verantwortung bei der Entwicklerin bzw. dem Entwickler: Sie bzw. er muss die Qualität und Sicherheit der KI-Ergebnisse validieren ³ ¹.
Genau darin liegt auch die Ambivalenz der Produktivitätsdebatte: KI kann Entwicklungsarbeit beschleunigen, aber nicht ohne zusätzliche Steuerung und Prüfung. Belastbare Feldstudien zur Produktivität gibt es unter anderem mit Entwickler:innen bei Microsoft und Accenture (Accenture hat kürzlich bekannt gegeben Copilot an alle seine ca. 745 Tausend Mitarbeitende auszurollen). In der Studie führte der Einsatz von Copilot zu mehr abgeschlossenen Pull Requests pro Woche: bei Microsoft je nach Modell um rund 13 bis 22 %, bei Accenture um rund 8 bis 9 % ¹⁰ (allerdings mit dem Hinweis, dass der Übertrag nicht immer auf andere Organisationen gemacht werden kann). Eine aktuellere DORA-Einordnung bestätigt aber diese Ambivalenz: KI beschleunigt insbesondere den Einstieg in Aufgaben und die erste Codegenerierung, verschiebt die eingesparte Zeit aber häufig in Prüfung, Auditierung und Verifikation ¹⁵. Auch wenn es bisher nur wenige konkrete Feldmessungen gibt und die Studie aus 2024 stammt, ist die Größenordnung plausibel: Unter der Annahme, dass Modelle leistungsfähiger werden und stärker in Entwicklungsprozesse integriert sind, sprechen auch aktuellere Einordnungen wie DORA dafür, Effizienzgewinne in diesem Rahmen zu erwarten.
Shift Left: Qualität verschiebt sich nach vorne
Unter „Shift Left“ versteht man, QA- und Testaufgaben frühzeitig in die Programmierphase zu verlagern, um Probleme idealerweise bereits während der Umsetzung zu entdecken ². KI-gestützte Werkzeuge können diesen Prozess unterstützen, indem sie aus Anforderungstexten automatisch Testszenarien ableiten oder reale Anwendungsszenarien simulieren ⁴. Entwickler:innen formulieren dafür anfangs Testfälle oder Spezifikationen (ähnlich dem Test-Driven Development), die dann vom Agenten umgesetzt und geprüft werden ⁵. So verlagern sich Qualitätsschleifen noch weiter nach vorne im Zyklus.
Dies erfordert eine höhere Genauigkeit bei der Anforderungsdefinition, da die Qualität von KI-generiertem Code stark davon abhängt, wie präzise Anforderungen und Prompts formuliert werden (unspezifische Eingaben führen sehr schnell zu Fehlern). Gleichzeitig müssen Randfälle bereits im Design berücksichtigt werden: Studien zeigen hier, dass generative Modelle bei komplexen Edge Cases oft nicht funktionieren ³.
Insgesamt werden klare Spezifikationen und umfassende Tests somit zum Produktivitätsmultiplikator. „Shift Left” führt zudem dazu, dass die Anforderungsdefinition und Validierung stärker teamübergreifend organisiert werden müssen. Produkt, Design und Technik teilen sich diese Aufgabe. Letztlich bleibt die Verantwortung für Test und Review beim Menschen, auch wenn KI die Erkennung von Fehlern beschleunigt ² ³.
Review wird wichtiger als Writing
In Verbindung mit der im vorherigen Absatz „Vom Implementieren zum Orchestrieren“ vorgenommenen Einordnung zur Produktivität und empirischen Analysen, die zeigen, dass KI-Tools etwa 1,7-mal mehr Fehler (einschließlich schwerer Bugs) produzieren als menschlicher Code ⁷, wird deutlich, dass das Review zu einer kritischen Kernkompetenz wird. An die Stelle des bloßen Programmierens tritt das schnelle Verstehen, Hinterfragen und Validieren von Ergebnissen. Der Fokus liegt dabei weniger auf Stilfragen, sondern auf Logik, Architektur und Edge Cases. Es geht darum sicherzustellen, dass der Code tatsächlich die Anforderungen erfüllt.
Das bedeutet auch: Die Verantwortung bleibt bei den Entwickler:innen. KI kann Vorschläge liefern, aber sie übernimmt keine Haftung für Fehler. Es entsteht Spannungsfeld zwischen Automatisierung und menschlicher Kontrolle ⁶ ⁷.
Sicherheitsaspekte gewinnen weiter an Bedeutung. Beispielsweise finden sich in etwa 12–18 % der KI-generierten Python-Codeblöcke CWE-Schwachstellen ⁸. In der Praxis verschiebt sich deshalb der Schwerpunkt auf gründliche Code-Reviews als Teil des Risikomanagements. Pull-Requests und formale Freigaben werden wichtiger, und Teams etablieren klarere Prüfprozesse für KI-Code. Langfristig entsteht ein Rollenbild, das eher an einen Auditor erinnert: Die Fähigkeit, Code rasch inhaltlich zu bewerten und Schwachstellen zu erkennen, wird zur zentralen Developer-Qualifikation.
Rapid Prototyping wird Standard, aber nicht das Ziel
GenAI übernimmt insbesondere in den Bereichen Design, Implementierung und Testvorbereitung und bringt Zeitersparnisse für die Erstellung früh lauffähiger Prototypen ⁹. Insgesamt wird von messbaren Produktivitätszuwächsen bei Softwareaufgaben insbesondere durch kürzere Iterationszyklen und mehr „erste Versionen“ berichtet ¹⁰. Rapid Prototyping wird häufiger als Standard genutzt, da Hypothesen schneller in ausführbare Ergebnisse übersetzt und mit Nutzerfeedback abgeglichen werden können ⁹. Gleichzeitig ist die Übertragbarkeit dieser frühen Ergebnisse auf produktionsnahe Implementierungen begrenzt, da Modelle bei stärker kontextabhängigen, abhängigen Programmierungen/Software-Projekten deutlich schlechter abschneiden als bei der Erstellung kleinteiligen Snippets und Tools ¹².
Die Folge ist eine stärkere Trennung zwischen „erste Version erzeugen“ und „robust machen“: Die erste Phase wird beschleunigt, während die zweite aufwandsintensiv bleibt und Architektur-, Schnittstellen- sowie Wartbarkeitsentscheidungen erfordert ¹². Aus DORA-Analysen geht hervor, dass die Adoption von KI zwar mit höherem Durchsatz in Verbindung stehen kann, aber weiterhin mit geringerer Lieferstabilität korreliert, wenn Kontrollmechanismen und Feedbackschleifen nicht ausreichend sind ¹¹. In diesem Sinne steigt das Risiko, dass schneller erzeugte Änderungen mehr Nacharbeit auslösen, wenn Validierung, Tests und Release-Disziplin nicht proportional mitsteigen ¹³. Große Repository-Studien über mehrere Assistenzsysteme hinweg zeigen zudem, dass KI-beeinflusste Commits häufig Code-Smells sowie nicht triviale Anteile an Bugs und Security-Issues einführen. Ein Teil dieser Probleme verbleibt über längere Zeit im Codebestand ¹³.
Damit wird die „Prototype Trap“ auch organisatorisch relevant: Prototypen, die ohne klare Übergabekriterien in den Produktivcode wandern, erhöhen die Wahrscheinlichkeit kumulierender Wartungs- und Qualitätskosten ¹⁵. In LLM-basierten Systemen entsteht ergänzend eine zusätzliche technische Schuld, weil kurzfristige Prompt- und Parameter-Tweaks als schnelle Fixes genutzt werden und sich verfestigen können (z.B. in Form von Self-Admitted Technical Debt, kurz SATD) ¹⁴. Rapid Prototyping ist somit vor allem ein Lerninstrument, dessen Ziel die schnellere Validierung von Problem und Lösung ist, nicht die schnellere Fertigstellung eines produktionsreifen Systems ⁹ ¹³. Praktisch bedeutet dies, dass Teams explizite „Definition of Prototype“- und „Definition of Done“-Grenzen benötigen, um die Übergänge in die Bereiche Stabilisierung, Security und Observability planbar zu machen.
Vom Narrativ zur Umsetzung: Wie wir weiter vorgehen
Wir sind dabei die Nutzung von Copilot und ergänzenden KI-Agenten bewusst zu begleiten. Wir nutzen unsere Metriken, um kontinuierlich zu beobachten wie sich unsere Arbeitsweisen über die Zeit verändern. Uns geht es nicht nur um Effizienz, sondern darum zu verstehen, wie sich die Rolle von Entwickler:innen konkret weiterentwickelt, und um sicherzustellen, dass alle bei uns in der Organisation Teil des Wandels sind. Damit orientieren wir uns auch an drei zentralen Erfolgsfaktoren aus der McKinsey-Studie: praxisnahes Training und individuelle Begleitung, das Tracking von Outcome-Metriken sowie klare KI-Ziele für Produkt- und Entwickler:innen-Rollen ¹.
Wir starten mit einigen konkreten Initiativen:
Review-Guidelines für KI-generierten Code: Es soll ein gemeinsames Verständnis darüber entwickelt werden, wie Code aus Copilot und Agenten bewertet wird. Welche typischen Fehlerbilder gibt es? Worauf achten wir bei Architektur, Sicherheit und Edge Cases? Ziel ist es, das Review als Kernkompetenz im Team systematisch zu stärken.
„Prompt Patterns“ und Best-Practices-Library: Sammlung wiederverwendbarer Prompts, Workflows und Patterns aus dem Team. Diese Sammlung ist keine statische Dokumentation, sondern eine lebendige Wissensbasis, die zeigt, wie komplexere Aufgaben strukturiert und effizient mit KI gelöst werden können.
Exploration und Stabilisierung müssen klar getrennt werden. Durch die Einführung klarer Phasen und Kriterien („Definition of Prototype“ vs. „Definition of Done“) wird das Rapid Prototyping bewusst genutzt, ohne dass technische Schulden aufgebaut werden. Die Teams entscheiden aktiv, wann eine Lösung explorativ bleibt und wann sie produktionsreif gemacht wird.
Ticket Engineering Guide als neue Kernkompetenz: Weiterentwicklung unserer Ticket-Struktur hin zu präzisen, KI-lesbaren Spezifikationen. Entwickler:innen werden bewusst früher eingebunden, um Anforderungen, Edge Cases und Akzeptanzkriterien mitzugestalten. Ziel ist es, Tickets nicht nur als Übergabepunkte, sondern als zentrale Steuerungsartefakte für Mensch und KI zu etablieren.
Quellen
- 1 McKinsey (2025), Unlocking the Value of AI in Software Development, McKinsey.com.
- 2 IBM (2023), Beyond Shift Left: How Shifting Everywhere With AI Agents Can Improve DevOps Processes, IBM Research / Think Insights.
- 3 Stack Overflow (2024), Developer Survey: Vertrauen in KI, Stack Overflow.
- 4 IBM (2023), Beyond Shift Left: How Shifting Everywhere With AI Agents Can Improve DevOps Processes, IBM Research / Think Insights (Testing-Abschnitt).
- 5 Morris, K. (2026), Humans and Agents in Software Engineering Loops.
- 6 SonarSource (2025), State of Code Developer Survey, SonarSource (insbesondere Vertrauens- und Review-Daten).
- 7 CodeRabbit (2025), AI Code Issues Study, CodeRabbit (Vergleich KI vs. menschliche Fehlerquote).
- 8 Schreiber, M. & Tippe, P. (2025), Security Vulnerabilities in AI-Generated Code, Lecture Notes in Computer Science, Vol. 16219.
- 9 The State of Generative AI in Software Development: Insights from Literature and a Developer Survey (2026), arXiv.
- 10 Cui, Z. et al. (2024), The Productivity Effects of Generative AI: Evidence from a Field Experiment with GitHub Copilot, MIT GenAI / PubPub.
- 11 Google Cloud (2025), State of AI-assisted Software Development (DORA Report 2025), Google Cloud Blog.
- 12 Du, X. et al. (2024), Evaluating Large Language Models in Class-Level Code Generation (ClassEval), ICSE.
- 13 Debt Behind the AI Boom: A Large-Scale Empirical Study of AI-Generated Code in the Wild (2026), arXiv.
- 14 Selvanayagam, N. et al. (2026), Self-Admitted Technical Debt in LLM Software: An Empirical Comparison with ML and Non-ML Software, arXiv.
- 15 DORA / Google Cloud (2026), Balancing AI tensions: Moving from AI adoption to effective SDLC use.