Praecura ist unsere SaaS-Plattform für die Versicherungsbranche. Als Cloud-Plattform müssen immer mehr Anforderungen zur Integration von Dritt-Systemen erfüllt und Daten aus mehreren Systemen zentralisiert werden, um auf dieser Grundlage Analysen und KI-Modelle zu entwickeln.
Die Herausforderung an uns als SaaS-Plattform-Anbieter
Versicherer, Makler und Vermittler, die unsere Plattform nutzen, haben oft mit noch nicht digitalisierten Prozessen und einer Vielzahl an Tools in der Gesamtlandschaft zu kämpfen – nicht zuletzt aufgrund der hohen regulatorischen Anforderungen.
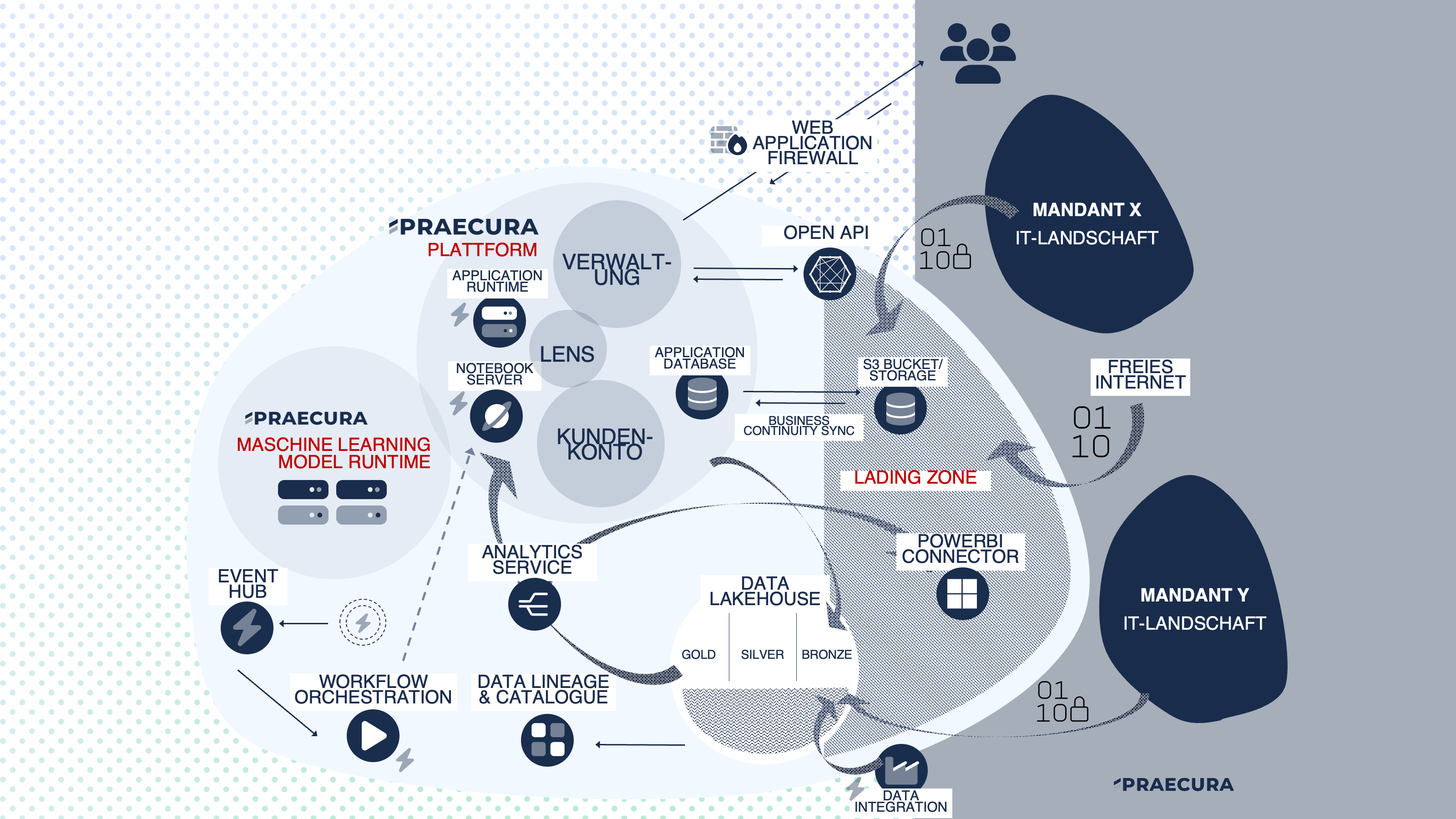
Wir haben uns daher entschlossen, die Möglichkeit und Flexibilität zu schaffen, mit Praecura als zentrale Plattform in der Mitte vieler anderer Drittsysteme zu stehen. An dieser Stelle sollen Daten zentralisiert und ausgewertet werden können, nicht zuletzt um unseren Anspruch als Workflow- und Prozessautomator gerecht zu werden. So ist der folgende Architekturansatz entstanden.
Anforderungen an die Analytics-Infrastruktur
Folgende Grundanforderungen stehen an unsere Infrastruktur:
Ablegen von strukturierten und und unstruktrierten Daten in verschiedenen Formaten, insbesondere auch Anreicherung der Umgebung mit externen Daten (sowohl von Mandanten, als auch freie Daten), als auch interne Daten aus der operativen Datenbanken.
Parallel-Verarbeitung von größeren Datenmengen.
Bundling/Kombination & Transformation von Datensätzen (Data Products) zu neuen Daten-Produkten.
Sichtbarkeit/Data Discovery fördern durch Dokumentation über die Transformationsschritte (Data Lineage) von Daten (latente vs nicht latente Daten) als auch Beschreibung von Metadaten (Data Catalogue).
Echtzeitverarbeitung von Daten / Reaktion auf Veränderungen innerhalb der Umgebung und Auslösen von nachfolgenden Prozessschritten.
Automatisierung von Datenpipelines.
Data Governance & IT Sicherheit: Zugriffskontrolle, Ablegen von Daten in einer vorgelagerten Zone.
Integration von Machine-Learning-Modellen (Zugriff auf die gesammte Datenbasis).
Die Beispiel-Architektur
Die Plattform erweitert sich um Komponenten, die die eigentliche Praecura-Plattform (Kundenkonto, Verwaltung, Lens) anreichern.
| Komponente | Beschreibung | Technologie |
|---|---|---|
| Landing Zone | Abgeschottete Zone für den sicheren Zugriff auf interne Ressourcen. Virtuelles Subnetz, in welchem Ressourcen gehostet werden, die dedizierten beschränkten Zugriff auf einzelne Komponenten der kritischen Infrastruktur bekommen (Private Endpoint Analogie). | z.B. Azure Virtual Network (VNET) oder AWS Virtual Private Cloud (VPC) |
| Data Lakehouse & Data Mesh | Datenspeicher für Analytics Zwecke: Konsolidierung von Daten / Data Mesh Konzept (Operational Database, Externe Marktdaten, Ergänzende internete Mandantendaten) Daten im Lakehouse werden im Textformat (Parquet, Delta, Avro) gespeichert, um große Datenmengen handhabbar zu machen. Seperierung in Bronze, Silver und Gold Layer (Evolution von Daten Produkten). | z.B. Azure Data Lake oder S3 Storage. Eigentlicht entsteht das Lakehouse erst aus der Kombination mehrere Technologien, die aber hier seperat aufgelistet werden: Data Lineage & Catalogue Analytics Server |
| Data Integration Runtime | Data Engineering: Niedrigschwellige Integration Runtime (Low Code), um Daten aus externen und internen Quellen zu laden und im Lakehouse abzulegen. ETK / ELT (E=Extract, L=Load, T=Transform). | z.B. Azure Data Factory, AWS Glue oder Airflow |
| Open-API | Direkte Interaktion/Anreicherung mit den Daten der Plattform (Query & Mutate), z.B. Masterdaten. Fokus: Daten, die für den Betrieb der Core-Plattform benötigt werden, nicht aber für Analytische Workloads. | Direkte Implementierung innerhalb der Core Plattform. |
| PowerBI Connector | Möglichkeit für Mandaten niedrigschwellig auf Daten im Lakehouse zuzugreifen, und so Daten aus dem Praecura Ökosystem im internen Power Bi Reporting der Mandaten direkt einbinden zu können (oft notwendig im Bereich des Exposure Managements). Zugriff hier aber nur auf das Data Lake über den Analytics Server. | Custom Self-Developed PowerBI Connector |
| Analytics Service | Daten im Lakehouse werden im Textformat (Parquet, Delta, Avro) gespeichert, um große Datenmengen handhabbar zu machen. Daher wird ein Analytics Server notwendig, um auf die Daten zugreifen zu können (Entkoppung von Compute und Storage wie in klassischen Datenbanken / Data Warehouses). | z.B. AWS Athena oder Azure Data Lake Analytics |
| Data Lineage & Catalog | Data Lineage Tool, um so Transformationsschritte von Daten (Evolution von Daten-Produkten) sichtbar zu machen. Datenkatolog, um so Metadaten (welche Informationen sind im Datensatz, wie aktuell sind diese, etc) zu kennzeichnen. | z.B. Amundsen oder Apache Atlas |
| Event Hub | Event Hubs als wesentliche Komponenten moderner Datenarchitekturen: Echtzeitverarbeitung von Daten. Entkopplung von Produzenten und Konsumenten. Zentrale Sammelnstelle von Events bei Veränderungen von Daten (einzelne Kompontenten im gesamten Ökosystem müssen Events auslösen, sodass man als Teil von Workflow Orchestration Tools darauf basierten Prozesse starten kann). | z.B. Azure Event Hub oder Azure Kinesis |
| Workflow Orchestration | Erstellen, Planen und Überwachen von Datenpipelines (Verbindung zum Notebook Server & Event Hub). | z.B. Airflow |
| Maschine Learning Model Runtime | Interne Ressource, um interne Maschine Learning Modelle ausführen und entwickeln zu können. Wir ausschließlich intern verwendet, um so Modelle für die Plattform bereit zu stellen (LLMs, Spracherkennung etc.) |
Wollt ihr mehr erfahren? Dann nehmt gerne Kontakt zu uns auf!